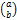For those of who wish to know what the problem is without clicking the link:
A circle of radius 1 cm is inscribed in an equilateral triangle. A smaller circle is inscribed at each vertex touching the first circle and tangent to the two 'containing' sides of the triangle. This process is continued ad infinitum...Now this might not be immediately obvious as the best way to approach this problem, so we need to think about what we know, what we need to know and the best way to approach this.

What is the sum of the circumferences of all the circles?What is the sum of their areas?Adding all the circumferences or adding all the areas, which sum grows faster?
What We Know:
- The radius of the largest circle is 1cm.
- All of the triangles angles are 60° as the triangle is an equilateral.
- The area of the first circle is π, the circumference is 2π.
What We Need To Know:
- The ratio of the radii from each circle to the next.
- The height of the triangle.
- The area of all the circles.
- The circumference of all the circles.
The height of the triangle may seem like a bit of a strange necessity, but if you know the diameter of the main circle (2cm) then it helps to know what the sum of the diameters of all of the circles will be (height-2).
Now if the the radius were arranged so it was at a right angle to the triangle and a line was drawn from the centre of the largest circle the corner of the side the radius touches the angle would be half of the original angle which is 60° so the new angle is 30°. This is hard to picture but an angle will help that.

Now we have two angles and one side, so we can use the Sin rule to find the size of the line from the centre of the circle to the corner of the triangle.

This means that the radius of the largest circle plus the diameters of all of the other circles is 2. So the height of the triangle 2 plus the radius of the larger circle, which equals 3. It also means that the sum of the diameters of all of the other circles equals 1 too.
Now we can begin to actually tackle the problem of the sum of the circumferences of all the circles. We already know that the circumference of the first circle is 2π, if the sum of all the diameters of the other circles in one line is 1 we can see that the area is then π, but we still have two other sets of circles. So we have the total circumference of 2π+π+π+π which means the total circumference is 5π. Problem one solved.
The second problem is slightly more awkward as the radius is not as easy to find and although the way I am about to explain does work in may not be the most efficient, but it does work and it utilises some very nice Core 2 techniques.
As you may have noticed, there will be an infinite number of circles going into any of the corners (this is caused by the curved shape of a circle against the straight side of the triangle). If we exclude the large circle then the sum of the diameters of into one corner is 1.
The fact that the triangles always get smaller, means that the rate at which they 'increase' is less than 1, we will call this ratio 1/n, the radius of the second triangle will also be 1/n because of the fact that the first radius is 1.
We know that the sum of the diameters equals 1, which means that the sum of 2*radius is also equal to 1. We also know the first term of this series (1/n), the ratio of the series (1/n) and the sum of the series (1). As our ratio is less than 0 we can use the formula covered in C2 for that:

Using that we can rearrange to find what n equals and thus find the ratio. I have included the original equilateral triangle image along with some labelling to help to explain my notation.

So we have that the ratio from radius to radius is 1/3, so to find the sum of the area of all the triangles we must use the sum of an infinite series again. Given that the first term is π (from πr^2 and r = 1), the ratio is r^2, which gives 1/9. We have three of the series so we will times the sum of these by 3, but then we have included the largest triangle three times, so we must subtract this two times (-2π).

This means that the area of all the circles is 11π/8, problem two solved.
The last problem is considerably easy to handle, it simply asks which sum grows faster, this is the one that has a larger ratio. Well the ratio of the area is 1/9, whereas the circumference is 2/3 (r is 1/3, but we want twice this). So this means the circumference increases faster.
This problem really is a lovely one, it combines some relatively simple maths in an advanced form, pieces them all together and leaves you to solve the puzzle. Maths is fun. Maths is really, really fun!
I realise I may have explained fair chunks of this poorly, it is very difficult to convey what is happening and without being in front of you. So if you are left with any questions as to what I have done, or why, simply leave a comment and I will explain or email me at lewis.mead@eloquentmath.com for more information.
Also to let you know, I will be completing a Core 2 revision guide pretty soon (give me a week or so), so keep checking back here for updates on that.