
I feel I needed an updated post on the Fibonacci sequence with some of the more core ideas behind it, you can still access the old post.
The definition of the Fibonacci sequence is:
$\begin{align}F_{n+2}=F_{n+1}=F_n\ where\ F_0=1,\ F_1=1\end{align}$
You can see quickly that the first few values of the sequence are 1, 1, 2, 3, 5, 8, 13, ..., etc. this is a weakly increasing sequence, that is ${F}_{n+1}\ge F_n \forall\ n \ge 1$.
This clearly means that the sequence does not tend towards a limit, but does the ratio between terms tend towards a limit?
Consider that the $\lim_{n\to\infty}(\frac{F_{n+1}}{F_n})=x$. If we divide $(1)$ through by $F_{n+1}$ we get:
$\begin{align*}\frac{F_{n+2}}{F_{n+1}}=1 + \frac{F_n}{F_{n+1}}\end{align*}\tag{2}$
Clearly from our definition of the $\lim_{n\to\infty}(\frac{F_{n+1}}{F_n})=x$ we get that $(2)\equiv x=1+\frac{1}{x}$. This is easy enough to solve, we simply multiply through by $x$ and rearrange to get a quadratic we can solve.
$\begin{align*}x^2-x-1=0
\\\Rightarrow x = \frac{1\pm\sqrt{5}}{2}\end{align*}$
Only one of these two possible x values are logical, as the sequence is weakly increasing and all of the terms are greater than or equal to 0 clearly the ratio between terms is positive $\therefore\ x = \frac{1+\sqrt{5}}{2}$. This is the golden ratio, $\phi$.
Our definition that $x=1+\frac{1}{x}$ has interesting implications when we represent it as a recurrence relation, $x_{n+1}=1+\frac{1}{x_n}$. If we set $x_0 = 1$ then $x_1 = 1+\frac{1}{1},\ x_2 = 1 + \frac{1}{1+\frac{1}{1}}$, etc. This continues on such that $\lim_{n\to\infty}(x_{n+1})\equiv\phi = 1 + \frac{1}{1+\frac{1}{1+\frac{1}{\ddots}}}$, this is an example of an infinite continued fraction.
A continued fraction is essentially fractions within fractions (frac-cep-tions?), $a_1 + \frac{1}{a_2 + \frac{1}{\ddots \, + \frac{1}{a_m}}}$.
An infinite continued fraction is one that does not terminate after a finite sequence of iterations, $a_1 + \frac{1}{a_2 + \frac{1}{\ddots}}$. An irrational number can be continually, more accurately, approximated using infinite continued fractions.
If we want to represent any integers as an infinite continued fractions we can begin by thinking of the general continued fraction:
$\begin{align*}a=\frac{k}{1+\frac{k}{1+\frac{k}{\ddots}}} \Rightarrow a=\frac{k}{1+a} \Rightarrow a^2+a-k=0\end{align*}\tag{3}$
For a to be rational in this quadratic $1+4k$ must be a square number, clearly this square will be odd (odd + even = odd) from this you can quickly calculate the first few values of k to be $k = 2,\ 6,\ 12,\ 20,\ ...$, it can be quickly shown that the nth term $k_n=n^2+n$. Using the quadratic formula on $(3)$ we find that $a=\frac{-1+\sqrt{4(n^2+n)+1}}{2}\equiv\frac{-1\pm\sqrt{(2n+1)^2}}{2}\equiv\frac{2n}{2}=n$.
Therefore for all positive integers, a, we can represent them as an infinite continued fraction if and only if $k=a^2+a$. Or to put it mathematically:
$a=\frac{k}{1+\frac{k}{1+\frac{k}{\ddots}}},\ a\in\mathbb{N} \Leftrightarrow k=a^2+a$
This is one example of how useful (and fun!) continued fractions can be, they are also much more mathematically relevant than decimals as they provide a lot more useful information about the nature of the number itself.
See if you can express $\sqrt{2}$ as an infinite continued fraction. Leave any answers in the comment section.
Wednesday, 19 December 2012
Friday, 26 October 2012
Modular Arithmetic: Rule of 3
Did you know that if a number is divisible by 3 then the sum of its digits are also divisible by 3? Have you ever wondered why? The answer to this problem lies within the field of modular arithmetic.
To begin we need to very precisely decide what our question really is. We start by defining some integer, n, with digits arar-1...a1a0. This then means that: n = a0 + 10a1 + ... + 10r-1ar-1 + 10rar.
In order to proceed with our proof we must first prove a simpler fact, that an - bn is always divisible by a - b. We will use induction to prove this lemma.

What this lemma means is that if a ≡ b mod m that an ≡ bn mod m, for any integer n, too. With this fact ready we can now proceed with our proof.
It is clear that 10 ≡ 1 mod 3 (10 - 1 can be perfectly divided by 3), utilising our lemma it is clear that 10k ≡ 1 mod 3. If a ≡ b mod m and c ≡ d mod m then ac ≡ bd mod m (the multiplicative law) and that (a + c) ≡ (b + d) mod m (the additive law), read the proofs here.
0 is obviously divisible by 3, hence ak - ak (the kkt n minus the same digit) is divisible by 3 too - this means that ak ≡ ak mod 3. Utilising the rules of modular arithmetic we have that 10kak ≡ ak mod 3. It then follows from the additive law that n ≡ (ar + ar-1 + ... + a1 + a0) mod 3.
Therefore if 3|n then (ar + ar-1 + ... + a1 + a0) ≡ 0 mod 3, or in English, the sum of the digits of a number that is divisible by 3 will also be divisible by 3. The rule of 3 is proven.
There are also similar laws for division by 9 and 11 but I will leave these proofs up to the reader of this post, you use the exact same techniques and facts as I have used here. Leave any comments on any problems (or successes!) you have with this.
To begin we need to very precisely decide what our question really is. We start by defining some integer, n, with digits arar-1...a1a0. This then means that: n = a0 + 10a1 + ... + 10r-1ar-1 + 10rar.
In order to proceed with our proof we must first prove a simpler fact, that an - bn is always divisible by a - b. We will use induction to prove this lemma.
What this lemma means is that if a ≡ b mod m that an ≡ bn mod m, for any integer n, too. With this fact ready we can now proceed with our proof.
It is clear that 10 ≡ 1 mod 3 (10 - 1 can be perfectly divided by 3), utilising our lemma it is clear that 10k ≡ 1 mod 3. If a ≡ b mod m and c ≡ d mod m then ac ≡ bd mod m (the multiplicative law) and that (a + c) ≡ (b + d) mod m (the additive law), read the proofs here.
0 is obviously divisible by 3, hence ak - ak (the kkt n minus the same digit) is divisible by 3 too - this means that ak ≡ ak mod 3. Utilising the rules of modular arithmetic we have that 10kak ≡ ak mod 3. It then follows from the additive law that n ≡ (ar + ar-1 + ... + a1 + a0) mod 3.
Therefore if 3|n then (ar + ar-1 + ... + a1 + a0) ≡ 0 mod 3, or in English, the sum of the digits of a number that is divisible by 3 will also be divisible by 3. The rule of 3 is proven.
There are also similar laws for division by 9 and 11 but I will leave these proofs up to the reader of this post, you use the exact same techniques and facts as I have used here. Leave any comments on any problems (or successes!) you have with this.
Saturday, 6 October 2012
Sets: An Introduction to Sets
A set is a very simple idea on the face of it, it is merely a collection or group; that is all. Sets are not objects in the real world; they are created within our minds not by our hands. An example of a set is all even numbers or all of the children in Europe or even the set of green bumblebees. But that is obviously not the sort of set we are interested in, we are only interested in ones that have interesting mathematical properties.
Sets by themselves may seem pretty uninteresting but when used in other areas of mathematics they show how powerful they truly are. They are used as a foundation from which the majority of mathematics can be derived, that is why they're so fundamentally important to mathematicians! Sets have to be defined in such a way that creates some list of numbers.
By convention, sets are denoted by capital letters, elements (read more in the next paragraph) are labelled by lower case letters. Beyond this the notation for sets is basic: you list each element, separated by a comma, and surround this list by curly braces, {}. For example, some set, Q, contains elements {p, q, r}.
There are a range of ways in which a set may be defined, either the items are defined using a semantic description for example: all of the odd integers or all prime numbers divisible by 4. Or you can define a set by listing the elements individually, for example: {2, 4, 8, 16}, with this version an ellipsis may be used to show that the set continues indefinitely in the same manner {3, 9, 27, 81, ...} like so.
A set constitutes of elements, an element is one distinct item that makes up a set. For example 1 is an element of the set of integers, the notation for an element, x, belonging to a set R is: x ∈ R. x ∉ R means x is not an element of R.
A subset is a set that entirely lies within another set, for example all prime numbers are integers. A ⊆ B means every element of A is also an element of B and this is read as "A is a subset of B". An interesting point from this definition is that for any set, S, every element of S is clearly also in S thus S is a subset of S (S ⊆ S). This is a bit strange so we introduce something more thorough than subsets and that is proper subsets: A is a proper subset of B if every element in A is also in B and there is at least one element in B that is not in A; this has the slightly different notation of A ⊂ B.
The next two you may be more familiar with if you have done maths past GCSE level you may have encountered them, they are union and intersection. A union B is essentially A and B, the notation for this is A ∪ B, it is everything that is in A and B. A intersection B is where A and B overlap and the notation for this is A ∩ B.
The union of all of the natural numbers {1, 2, 3, ...} and all of the integers {-2, -1, 0, 1, 2, ...} will result in just the set of integers, the reason for this is that it does not matter if a set contains duplicate identical elements it is the same as long as the same elements are present, not how many. {1, 2, 3} is the same set as {1, 1, 2, 3, 2, 3} as the same elements are present in both. It then follows that A ∪ B = A + B - A ∩ B, which is a vitally important fact for combining sets.
You may also be interested in the size of infinite sets, which investigates that there are some infinities larger than others!
Sets by themselves may seem pretty uninteresting but when used in other areas of mathematics they show how powerful they truly are. They are used as a foundation from which the majority of mathematics can be derived, that is why they're so fundamentally important to mathematicians! Sets have to be defined in such a way that creates some list of numbers.
By convention, sets are denoted by capital letters, elements (read more in the next paragraph) are labelled by lower case letters. Beyond this the notation for sets is basic: you list each element, separated by a comma, and surround this list by curly braces, {}. For example, some set, Q, contains elements {p, q, r}.
There are a range of ways in which a set may be defined, either the items are defined using a semantic description for example: all of the odd integers or all prime numbers divisible by 4. Or you can define a set by listing the elements individually, for example: {2, 4, 8, 16}, with this version an ellipsis may be used to show that the set continues indefinitely in the same manner {3, 9, 27, 81, ...} like so.
A set constitutes of elements, an element is one distinct item that makes up a set. For example 1 is an element of the set of integers, the notation for an element, x, belonging to a set R is: x ∈ R. x ∉ R means x is not an element of R.
A subset is a set that entirely lies within another set, for example all prime numbers are integers. A ⊆ B means every element of A is also an element of B and this is read as "A is a subset of B". An interesting point from this definition is that for any set, S, every element of S is clearly also in S thus S is a subset of S (S ⊆ S). This is a bit strange so we introduce something more thorough than subsets and that is proper subsets: A is a proper subset of B if every element in A is also in B and there is at least one element in B that is not in A; this has the slightly different notation of A ⊂ B.
The next two you may be more familiar with if you have done maths past GCSE level you may have encountered them, they are union and intersection. A union B is essentially A and B, the notation for this is A ∪ B, it is everything that is in A and B. A intersection B is where A and B overlap and the notation for this is A ∩ B.
The union of all of the natural numbers {1, 2, 3, ...} and all of the integers {-2, -1, 0, 1, 2, ...} will result in just the set of integers, the reason for this is that it does not matter if a set contains duplicate identical elements it is the same as long as the same elements are present, not how many. {1, 2, 3} is the same set as {1, 1, 2, 3, 2, 3} as the same elements are present in both. It then follows that A ∪ B = A + B - A ∩ B, which is a vitally important fact for combining sets.
You may also be interested in the size of infinite sets, which investigates that there are some infinities larger than others!
Wednesday, 3 October 2012
Why Does -1 × -1 = 1?
It may seem obvious that -1 × -1 = 1, but is it really as intuitive as it seems? In fact, really, it isn't nearly as obvious as it may appear and the proof can be nowhere near as rigorous as you would normally require one to be but it has to suffice because of how 'basic' the idea is.
The proof relies on the distributive law of arithmetic, which is that a(b + c) = ab + ac, this is so obvious to most of you that it may seem redundant even to state it but it is from this simple fact that the proof lies.
We will show that -1 × -1 = 1 by contradiction. We can obviously state that -1 × -1 = 1 or -1, then we assume that -1 × -1 = -1 is true. Consider -1(1 - 1) then by the distributive law we have that this equals to: -1 × 1 + -1 × -1 which from our assumption is -1 - 1 = -2. But this would then imply that -1 × 0 = -2 which is contradictory therefore -1 × -1 = 1 (which would make the equation we considered hold true, try it yourself).
This is a rather difficult proof to fully trust because we have made a pretty huge assumption, why must -1 × -1 = 1 or -1? Well, essentially, it doesn't have to but it just seems logical that it would be. As it is such a fundamental part of mathematics it is essentially defined by us in order for fundamental laws to continue to work. So if you find that the 'proof' I have given you is not enough then that's fine, it is true simply because it functions correctly..
The proof relies on the distributive law of arithmetic, which is that a(b + c) = ab + ac, this is so obvious to most of you that it may seem redundant even to state it but it is from this simple fact that the proof lies.
We will show that -1 × -1 = 1 by contradiction. We can obviously state that -1 × -1 = 1 or -1, then we assume that -1 × -1 = -1 is true. Consider -1(1 - 1) then by the distributive law we have that this equals to: -1 × 1 + -1 × -1 which from our assumption is -1 - 1 = -2. But this would then imply that -1 × 0 = -2 which is contradictory therefore -1 × -1 = 1 (which would make the equation we considered hold true, try it yourself).
This is a rather difficult proof to fully trust because we have made a pretty huge assumption, why must -1 × -1 = 1 or -1? Well, essentially, it doesn't have to but it just seems logical that it would be. As it is such a fundamental part of mathematics it is essentially defined by us in order for fundamental laws to continue to work. So if you find that the 'proof' I have given you is not enough then that's fine, it is true simply because it functions correctly..
Tuesday, 28 August 2012
Creating a Prime Checker
For this post I will be utilising Fermat's Little Theorem to check for primes from a certain number to another number, of course you can make it check just one number if you so wish. If you do not want to program it yourself you can feel free to just download my .exe prime checker, download my source code or you may want to download my list of the first 7,000,000 prime numbers created with this prime checker.
I will be using Python to create this for a few reasons but the most important of these is that Python is very useful in the sense that it does not cap the size of a number you wish to store - which is vitally important for this program as the numbers will get very, very large. Before I start you may want to read some of my posts on basic programming in Python:
Introduction to Python
Python: Mathematical Terminology
Python: Interaction and Variables
Fermat's little theorem is that ap-1/p always has a remainder of 1 for a prime p that is co-prime to a. And utilising this fact is how we check for a number being prime or not. One problem with Fermat's little theorem is that it can also occasionally work for when p is not actually prime (this is called a Poulet number), these are rare but to minimise the probability that the number isn't actually prime is to check the number with a different value of a multiple times.
Before we begin we need to be able to check what the highest common factor of two numbers actually is (in this case it will be a and p). To do this we will use the Euclidean algorithm, if you read that post it will tell you how to create that function and also what each part means. For the purposes of this program I will simply give you the code needed.
If the number cannot be expressed in the form 6n + 1 with n as an integer then the check is stopped there and the number is returned as not being prime, if it does meet that criteria then the Fermat primality check is performed. After the prime check is performed the outcome is returned (whether prime is True or False).
This is it for the coding of the actual prime checker, the rest of the programming is to give the program structure, variables and how to save the outcome of each check.
And that is it for the whole program! Hopefully yours is now working correctly, if you have any problems please leave a comment and I will help you as soon as I can. If you haven't already you may wish to download my .exe prime checker, download my source code or you may want to download my list of the first 7,000,000 prime numbers created with this prime checker.
I will be using Python to create this for a few reasons but the most important of these is that Python is very useful in the sense that it does not cap the size of a number you wish to store - which is vitally important for this program as the numbers will get very, very large. Before I start you may want to read some of my posts on basic programming in Python:
Fermat's little theorem is that ap-1/p always has a remainder of 1 for a prime p that is co-prime to a. And utilising this fact is how we check for a number being prime or not. One problem with Fermat's little theorem is that it can also occasionally work for when p is not actually prime (this is called a Poulet number), these are rare but to minimise the probability that the number isn't actually prime is to check the number with a different value of a multiple times.
Before we begin we need to be able to check what the highest common factor of two numbers actually is (in this case it will be a and p). To do this we will use the Euclidean algorithm, if you read that post it will tell you how to create that function and also what each part means. For the purposes of this program I will simply give you the code needed.
def gcd(a,b):Now we get down to the good bit and properly begin programming the prime checker!
while b != 0:
a, b = b, a%b
return a
def primecheck(num):We begin by creating a new user-defined function called 'primecheck', it will require one variable, which we will call 'num'. Python uses indentation to distinguish between different code segments and functions, so everything contained within the function will be indented. Three local variables will be required for the function, one to be used as a counter for when repeating Fermat's prime check to reduce the chance that the number is a Poulet number, one to be used as the 'a' in Fermat's little theorem and one to return whether the number is prime or not.
count = 0
a = 2
prime = True
if (num - 1)/6 == int((num-1)/6) and (num - 5)/6 == int(num - 5)/6):Now that we have the local variables for the function we can begin writing the code needed to check if a number is prime or not. The algorithm itself takes a fairly long time, so we want to begin by trying to get rid of numbers that are obviously not prime without needing to do very much to the number. All prime numbers (other than 2 and 3) can be written in the form 6n + 1 or 6n + 5 (why?), so we can check that our number satisfies this before we proceed with the more processor heavy check.
{Fermat's prime check}
else:
prime = False
return prime
If the number cannot be expressed in the form 6n + 1 with n as an integer then the check is stopped there and the number is returned as not being prime, if it does meet that criteria then the Fermat primality check is performed. After the prime check is performed the outcome is returned (whether prime is True or False).
while (count < 10):The check is performed 10 times with a different value of a to ensure that the number is not a Poulet prime, that is why there is a loop while count is less than 10. The loop starts by making a note that the check has been performed by increasing count by 1, a check is then performed to ensure that a and num are coprime, if they are not a is changed and the check is reperformed. Once a and num are coprime we utilise the pow function, pow(a,b,c) returns the remainder of ab/c; so in this code we are utilising this function to utilise Fermat's little theorem to check that num is prime by finding the remainder of anum - 1/num and if this is not 1 then the test has failed and num is immediately returned as false. If all the checks come back with no problems then num is returned as prime.
count = count + 1
while gcd(a, num) != 1: a = a + 1 if pow(a, num - 1, num) != 1: count = 10 prime = False a = a + 1
This is it for the coding of the actual prime checker, the rest of the programming is to give the program structure, variables and how to save the outcome of each check.
num = input("First prime to check ")To begin two variables are created for the first prime number to check and the last prime number to check in order to give the program an end point. While the number to be checked is less than the last number a check will be performed. A boolean variable prime is assigned to the output of the primecheck when performed on num. If prime is true then a text document called primes is opened to append and the number is added to it, read more on editing files from within Python. A message is displayed to the user to state whether the number is or is not prime. 2 is added to the previous number to ensure that the next number is odd, this relies on the fact that the first number entered was also odd, if it was not then you would be checking whether or not only even numbers are prime which obviously they will not be (except 2).
lastnum = input("Last prime to check ")
while num <= lastnum:
prime = primecheck(num)
if prime == True:
FILE = open("primes.txt", "a")
FILE.write(str(num))
FILE.write(", ")
FILE.close()
print num," is prime."
else:
print num, " is not prime."
num = num + 2
And that is it for the whole program! Hopefully yours is now working correctly, if you have any problems please leave a comment and I will help you as soon as I can. If you haven't already you may wish to download my .exe prime checker, download my source code or you may want to download my list of the first 7,000,000 prime numbers created with this prime checker.
Monday, 27 August 2012
Highest Common Factor: Proving Euclid's Algorithm
The Euclidean algorithm will find the highest common factor of two numbers (the largest number that will divide both numbers). It is a rather simple algorithm to understand and implement having been discovered by the great mathematician Euclid of Alexandria 300 BC making it one of the oldest algorithms still applicable and in use in modern times.
1.) Begin by inputting two numbers m and n
2.) If m < n then swap m and n (the larger number should be set to m)
3.) Divide m by n then get the remainder from this, r. If r = 0 then return n as the highest common factor and stop the algorithm.
4.) Let m = n and n = r. Repeat step 3.
The obvious questions here are "why does this work?" and "how do you know that the answer is always correct?". The best way to answer these questions is through an example.
Example: Find the highest common factor of 216 and 38.
From the algorithm we must set m = 216 and n = 38, m/n gives a remainder of 26. We now set m = 38 and n = 26, m/n gives a remainder of 12. Set m = 26 and n = 12, m/n gives a remainder of 2. Set m = 12 and n = 2, m/n gives a remainder of 0 so the highest common factor of 216 and 38 is 2.
It is clear from this algorithm that the important element from one step to the next relies on the fact that hcf(m,n) = hcf(n,r) is true. We will write this as a lemma.

This is how the algorithm works but it is not a proof as to that it will always work on any two integers, m and n. To prove this we will utilise how the algorithm in a more formal sense and then utilise those facts to prove the algorithm is consistent and thus correct.

And that is how and why the Euclidean algorithm works! It is relatively simple to program this algorithm and because of this and that it is very efficient it has many uses in mathematical programs, most importantly (to me!) is for prime checkers.
Overview of Euclidean Algorithm
1.) Begin by inputting two numbers m and n
2.) If m < n then swap m and n (the larger number should be set to m)
3.) Divide m by n then get the remainder from this, r. If r = 0 then return n as the highest common factor and stop the algorithm.
4.) Let m = n and n = r. Repeat step 3.
The obvious questions here are "why does this work?" and "how do you know that the answer is always correct?". The best way to answer these questions is through an example.
Example: Find the highest common factor of 216 and 38.
From the algorithm we must set m = 216 and n = 38, m/n gives a remainder of 26. We now set m = 38 and n = 26, m/n gives a remainder of 12. Set m = 26 and n = 12, m/n gives a remainder of 2. Set m = 12 and n = 2, m/n gives a remainder of 0 so the highest common factor of 216 and 38 is 2.
It is clear from this algorithm that the important element from one step to the next relies on the fact that hcf(m,n) = hcf(n,r) is true. We will write this as a lemma.
This is how the algorithm works but it is not a proof as to that it will always work on any two integers, m and n. To prove this we will utilise how the algorithm in a more formal sense and then utilise those facts to prove the algorithm is consistent and thus correct.
And that is how and why the Euclidean algorithm works! It is relatively simple to program this algorithm and because of this and that it is very efficient it has many uses in mathematical programs, most importantly (to me!) is for prime checkers.
Sunday, 15 July 2012
Understanding the Higgs Boson
Unless you have been hiding under a rock somewhere you will almost certainly have seen the news that the Higgs boson has been 'discovered', I say this tentatively as it has not officially been confirmed just a 'Higgs-like' particle has been observed. But what even is the Higgs boson?
By the 1970s physicists had devised what is known as the "Standard Model" of particle physics - it is a theory of the elementary particles, how they interact with each other and what these interactions mean. The elementary particles can be broken down into two core categories: fermions and bosons. Fermions are matter particles, they are what make protons, atoms, stars and us, whereas bosons are what helps the fermions to "communicate", this communication is called a force.
The standard model predicted the existence of a lot of particles far before they were discovered: the bottom quark, top quark, tau neutrino and the Higgs boson. All of these particles were required for the standard model to work in it's current form. In 1964 Peter Higgs (as well as Robert Brout and Francois Englert) devised a theory (that was later proven) for how elementary particles are able to have mass, this was called the Higgs mechanism.
The Higgs mechanism requires a field pervading through the whole universe and depending on how particles interact with this field dictates what mass they have, this is called the Higgs field. In quantum theory when a field interacts with another object it acts as a particle. In the electromagnetic field this particle is a photon, in the Higgs field the particle is the Higgs boson. The discovery of this particle means that the equations that are currently in place are correct and able to describe every particle we know about and how these particles interact together via the forces incorporated in the standard model (all except gravity), so essentially we now certainly understand the quantum world to a great deal of precision!
The reason the Higgs boson has eluded us for so long is that it is very, very unstable and decays incredibly quickly - in fact it only exists for approximately one zeptosecond, a thousandth of a billionth of a billionth of a second. Because it exists for such a short amount of time you have to observe the after effects of a collision and map how much energy the produced particles have and compare this to what you would expect if a Higgs boson had decayed, the problem is that it can decay into a lot of things. So you have to perform a lot of high energy collisions between particles, observe the data and see if it fits the predictions about how the Higgs boson should behave.
It has no electric charge or spin
Read about how the Higgs interacts with other particles
But is this it? Do we understand everything now that we have discovered the long elusive 'God particle' (a terrible, terrible term coined by the media)? The answer is a wonderfully fanatic, no! Thankfully. In fact, the discovery really means that we can now raise more questions and further advance our understanding of everything. At the smallest scale gravity is still a total mystery to us, it is not incorporated into the current standard model at all - one of the most primitive every day forces is still a complete mystery to us! Quantum mechanics and general relativity need to be united before we can even begin to ponder that we understand everything, we are some way off from a theory of everything but the best hat in the ring currently is string theory.
Just as one final note, the Higgs boson has not been officially confirmed as to existing but that a new, previously unknown boson with a mass between 125-127 GeV/c2 that has behaviour "consistent with" a Higgs particle. Further analysis is required to fully confirm it's existence but a very cautious tick is currently next to it!
By the 1970s physicists had devised what is known as the "Standard Model" of particle physics - it is a theory of the elementary particles, how they interact with each other and what these interactions mean. The elementary particles can be broken down into two core categories: fermions and bosons. Fermions are matter particles, they are what make protons, atoms, stars and us, whereas bosons are what helps the fermions to "communicate", this communication is called a force.
The standard model predicted the existence of a lot of particles far before they were discovered: the bottom quark, top quark, tau neutrino and the Higgs boson. All of these particles were required for the standard model to work in it's current form. In 1964 Peter Higgs (as well as Robert Brout and Francois Englert) devised a theory (that was later proven) for how elementary particles are able to have mass, this was called the Higgs mechanism.
The Higgs mechanism requires a field pervading through the whole universe and depending on how particles interact with this field dictates what mass they have, this is called the Higgs field. In quantum theory when a field interacts with another object it acts as a particle. In the electromagnetic field this particle is a photon, in the Higgs field the particle is the Higgs boson. The discovery of this particle means that the equations that are currently in place are correct and able to describe every particle we know about and how these particles interact together via the forces incorporated in the standard model (all except gravity), so essentially we now certainly understand the quantum world to a great deal of precision!
{kind=link}
The reason the Higgs boson has eluded us for so long is that it is very, very unstable and decays incredibly quickly - in fact it only exists for approximately one zeptosecond, a thousandth of a billionth of a billionth of a second. Because it exists for such a short amount of time you have to observe the after effects of a collision and map how much energy the produced particles have and compare this to what you would expect if a Higgs boson had decayed, the problem is that it can decay into a lot of things. So you have to perform a lot of high energy collisions between particles, observe the data and see if it fits the predictions about how the Higgs boson should behave.
Properties of Higgs Boson:
Mass: 126 GeV/c2 which is equivalent to 2.25 × 10-25kg or 134 protons.It has no electric charge or spin
Read about how the Higgs interacts with other particles
But is this it? Do we understand everything now that we have discovered the long elusive 'God particle' (a terrible, terrible term coined by the media)? The answer is a wonderfully fanatic, no! Thankfully. In fact, the discovery really means that we can now raise more questions and further advance our understanding of everything. At the smallest scale gravity is still a total mystery to us, it is not incorporated into the current standard model at all - one of the most primitive every day forces is still a complete mystery to us! Quantum mechanics and general relativity need to be united before we can even begin to ponder that we understand everything, we are some way off from a theory of everything but the best hat in the ring currently is string theory.
Just as one final note, the Higgs boson has not been officially confirmed as to existing but that a new, previously unknown boson with a mass between 125-127 GeV/c2 that has behaviour "consistent with" a Higgs particle. Further analysis is required to fully confirm it's existence but a very cautious tick is currently next to it!
Monday, 9 July 2012
Fermat's Little Theorem
Before reading through this post it is useful if you have some knowledge of modular arithmetic.
Fermat's little theorem (it's 'little' because of Fermat's comparatively more difficult to prove last theorem, not because it is less useful, in fact it is more useful) is a vital result from the field of number theory as it provides a method of checking (within reason) whether a number is prime or not. Also it is a very interesting result that utilises modular arithmetic.
Fermat's little theorem is that given a prime number, p, and any integer, a, ap - a will divide by p to give an integer value. Or, more mathematically, p|ap - a. So from the definitions in modular arithmetic this means that ap ≡ a (mod p); it can also be wrote as ap-1 ≡ 1 (mod p) - both are equally valid but the second is used more often mainly because it has a 1 on the right hand side and this is 'neater' and mathematicians love things to be neat!
There is a condition for the integer a and that is that it is coprime to p. Coprime means that the highest common factor between two numbers is 1; so for example 3 and 46 are coprime as the only factor they have in common is 1. The reason for why a must be coprime to p will come later.
When Pierre de Fermat first stated this theorem in a letter to his friend (in 1640) he did not include a proof of why this is the case as it was "too long". To attempt to 'one up' one of the greatest mathematicians in the past 400 years I will include a proof of this fact.

There are three points of contention within this proof that I feel I should justify/explain further. (A) is that these numbers are chosen intelligently in order to prove Fermat's little theorem, this was not the original proof of the theorem as it is difficult to be able to choose these numbers initially but in hindsight it is clear that these work very well.
(B) requires further explanation. The reason that when a, 2a, 3a,..., (p - 1)a are divided by p will give remainders 1, 2, 3,..., (p - 1) in some order is because of Euclid's lemma, if a prime number divides the product of two numbers then the prime number must divide at least one of the factors. Clearly none of the numbers in list A can be divided by p (a is coprime to p), so some integer in the range of list B, n, is coprime to p too - this means that na can not be divided by p so this means that a, 2a, 3a,..., (p - 1)a when divided by p must have remainders in the region of 1, 2, 3,..., (p - 1). Read more on this.
For (C) why can we cancel out (p - 1)! in modular arithmetic? It isn't an equals sign after all. If we consider ax ≡ ay (mod n), this means that ax - ay can be divided by n, factorising this we get a(x - y) can be divided by n implying that either a can be divided by n or x - y can be. In our case a is (p - 1)!, x is ap - 1 and y is 1; but (p - 1)! is clearly coprime to p so that means that ap - 1 - 1 can be divided by p so we can in fact cancel the (p - 1)!s.
And that is Fermat's little theorem fully proved! You will have almost certainly encountered Fermat's little theorem whether you knew it or not, almost all online security and encryption utilises prime numbers to stop data being intercepted and Fermat's little theorem is used to check the primality of numbers to be used.
If you do not understand anything in this post, feel I have made a mistake or need extra explanation on anything covered here leave a comment and I will get back to you as soon as I can.
Fermat's little theorem (it's 'little' because of Fermat's comparatively more difficult to prove last theorem, not because it is less useful, in fact it is more useful) is a vital result from the field of number theory as it provides a method of checking (within reason) whether a number is prime or not. Also it is a very interesting result that utilises modular arithmetic.
Fermat's little theorem is that given a prime number, p, and any integer, a, ap - a will divide by p to give an integer value. Or, more mathematically, p|ap - a. So from the definitions in modular arithmetic this means that ap ≡ a (mod p); it can also be wrote as ap-1 ≡ 1 (mod p) - both are equally valid but the second is used more often mainly because it has a 1 on the right hand side and this is 'neater' and mathematicians love things to be neat!
There is a condition for the integer a and that is that it is coprime to p. Coprime means that the highest common factor between two numbers is 1; so for example 3 and 46 are coprime as the only factor they have in common is 1. The reason for why a must be coprime to p will come later.
When Pierre de Fermat first stated this theorem in a letter to his friend (in 1640) he did not include a proof of why this is the case as it was "too long". To attempt to 'one up' one of the greatest mathematicians in the past 400 years I will include a proof of this fact.
There are three points of contention within this proof that I feel I should justify/explain further. (A) is that these numbers are chosen intelligently in order to prove Fermat's little theorem, this was not the original proof of the theorem as it is difficult to be able to choose these numbers initially but in hindsight it is clear that these work very well.
(B) requires further explanation. The reason that when a, 2a, 3a,..., (p - 1)a are divided by p will give remainders 1, 2, 3,..., (p - 1) in some order is because of Euclid's lemma, if a prime number divides the product of two numbers then the prime number must divide at least one of the factors. Clearly none of the numbers in list A can be divided by p (a is coprime to p), so some integer in the range of list B, n, is coprime to p too - this means that na can not be divided by p so this means that a, 2a, 3a,..., (p - 1)a when divided by p must have remainders in the region of 1, 2, 3,..., (p - 1). Read more on this.
For (C) why can we cancel out (p - 1)! in modular arithmetic? It isn't an equals sign after all. If we consider ax ≡ ay (mod n), this means that ax - ay can be divided by n, factorising this we get a(x - y) can be divided by n implying that either a can be divided by n or x - y can be. In our case a is (p - 1)!, x is ap - 1 and y is 1; but (p - 1)! is clearly coprime to p so that means that ap - 1 - 1 can be divided by p so we can in fact cancel the (p - 1)!s.
And that is Fermat's little theorem fully proved! You will have almost certainly encountered Fermat's little theorem whether you knew it or not, almost all online security and encryption utilises prime numbers to stop data being intercepted and Fermat's little theorem is used to check the primality of numbers to be used.
If you do not understand anything in this post, feel I have made a mistake or need extra explanation on anything covered here leave a comment and I will get back to you as soon as I can.
Sunday, 10 June 2012
Challenge Question 1: Solutions
This is the worked solution to Challenge Question 1.
To begin thinking about the problem it is a must to visualise or draw out what is actually going on and begin labelling what we know.
As all that matters in this question is the ratio from side to side we can say that the largest square has a side length of 1, the next is 1/2, the next 1/4, etc. This means that the area of the first square is 1, then next is 1/4, the next 1/16, etc.

You can see that there is a ratio of 1/4 between the area of a square and the square before it. So to find the total area of all the squares you can use the formula for the sum of an infinite geometric series a/(1 - r) (explained here), multiply it by 4 (for each branch) and then add 1 (for the central square). So we get [4 × 0.25/(1 - 0.25)] + 1, which gives a total area for the squares as 7/3.
Now for the area of the shaded squares. The first shaded square has a side length of 1/4, so it has an area of 1/16, the next shaded square has a side length of 1/8 and an area of 1/64. You can see that the ratio from the area of one square to the next is 1/16. The total area of the shaded squares uses the sum of an infinite geometric series again and multiplies it by 4 (for each branch). So we get 4 × 0.125/(1 - 1/16), which equals 8/15.
So the area of all the overlapping squares is 8/15 and the total area of all the squares is 7/3, so the proportion of the shaded squares is 8/15 ÷ 7/3 = 0.22857142857... So the final answer is that the shaded squares occupy 22.86% of the total area of the squares.
To begin thinking about the problem it is a must to visualise or draw out what is actually going on and begin labelling what we know.
As all that matters in this question is the ratio from side to side we can say that the largest square has a side length of 1, the next is 1/2, the next 1/4, etc. This means that the area of the first square is 1, then next is 1/4, the next 1/16, etc.

You can see that there is a ratio of 1/4 between the area of a square and the square before it. So to find the total area of all the squares you can use the formula for the sum of an infinite geometric series a/(1 - r) (explained here), multiply it by 4 (for each branch) and then add 1 (for the central square). So we get [4 × 0.25/(1 - 0.25)] + 1, which gives a total area for the squares as 7/3.
Now for the area of the shaded squares. The first shaded square has a side length of 1/4, so it has an area of 1/16, the next shaded square has a side length of 1/8 and an area of 1/64. You can see that the ratio from the area of one square to the next is 1/16. The total area of the shaded squares uses the sum of an infinite geometric series again and multiplies it by 4 (for each branch). So we get 4 × 0.125/(1 - 1/16), which equals 8/15.
So the area of all the overlapping squares is 8/15 and the total area of all the squares is 7/3, so the proportion of the shaded squares is 8/15 ÷ 7/3 = 0.22857142857... So the final answer is that the shaded squares occupy 22.86% of the total area of the squares.
Friday, 8 June 2012
SOLVED: Challenge Question 2
If you are the first to solve this problem I will give you complete set of the Richard Feynman Lectures on Physics (read up upon the Feynman Lectures on Physics).
Question:
A man, who is 1.65m tall, wishes to find the height of a tree with a shadow 36.52m long. He walks 24.12m from the base of the tree along the shadow of the tree until his head is in a position where the tip of his shadow exactly overlaps the end of the tree top's shadow. How tall is the tree? Round to the nearest hundredth.
Leave answers either in the comments box or contact me with the answer through our contact page or email me at rouge.ray@gmail.com.
Question:
A man, who is 1.65m tall, wishes to find the height of a tree with a shadow 36.52m long. He walks 24.12m from the base of the tree along the shadow of the tree until his head is in a position where the tip of his shadow exactly overlaps the end of the tree top's shadow. How tall is the tree? Round to the nearest hundredth.
Leave answers either in the comments box or contact me with the answer through our contact page or email me at rouge.ray@gmail.com.
Thursday, 7 June 2012
AQA C2 2012 Unofficial Worked Answers
A lot of people found this paper very difficult as some of the questions required more thought than usual. I didn't actually sit this paper, so I couldn't wait to get the paper to see why people found it so difficult. I managed to get hold of the paper so I thought I would share my answers.
You may wish to first download the June C2 2012 paper.











You may wish to first download the June C2 2012 paper.
a.) d = 9
b.) U100 = 23 + 99(9)
U100 = 914
c.) Sn = 0.5n[2a + (n-1)d]
S280 = 140[2(23) + 279(9)]
S280 = 357,980
a.) Area = 0.5 × 26 × 31.5 × 5/13
Area = 157.5cm2
b.) cos(sin-1(5/13))
12/13
c.) AC2 = 262 + 31.52 - (2 × 26 × 31.5 × 12/13)
AC2 = 156.25
AC = 12.5cm
a.) x3 - 2x3/2 + 1
b.) 0.25x4 - 0.8x5/2 + x + c
c.) (0.25(4)4 - 0.8(4)5/2 + 4) - (0.25(1)4 - 0.8(1)5/2 + (1))
42.4 - 0.45
41.95
a.) U1 = 12
U2 = 3
b.) r = 0.25
c.) S∞ = a/(1-r)
S∞ = 12/(1-0.25)
S∞ = 16
d.) U4 = 48(0.25)4 = 0.1875
S∞ = 0.1875/(1-0.25)
S∞ = 0.25
a.) rθ = 18(2π/3)
rθ = 12π
rθ = 12π
b.) i.) α = 2(π - π/3 - π/2)
α = π/3
ii.) PT = QT = 18tan(π/3) = 18√3
Area of two triangles = 2 × 0.5 × 18 × 18√3 = 324√3
Area of sector = 0.5 × 182 × 2π/3 = 108π
Shaded area = 324√3 - 108π = 221.8924551m2
Shaded area = 222m2 to 3 significant figures
a.) i.) f'(2) = 3(2)2 - 4/22 - 11
12 - 1 - 11 = 0
ii.) f''(x) = 6x + 8x-3
f''(2) = 6(2) + 8(2)-3
f''(2) = 13
iii.) f''(x) > 0, so it is a minimum point
b.) y = x3 + 4x-1 -11x + c
1 = 23 + 4(2)-1 -11(2) + c
1 = 8 + 2 - 22 + c
c = 13, so the equation is:
y = x3 + 4x-1 -11x + 13
a.) tanθ + 1 = 0 or sin2θ - 3cos2θ = 0
tanθ = -1
sin2θ = 3cos2θ, divide through by cos2θ to get:
tan2θ = 3
tanθ = ±√3
tanθ = -√3, -1, √3
b.) θ = -45°, 135°, -60°, 120°, 60°
θ = 60°, 120°, 135°
a.) It must go through (0,1)
b.) i.) 7x = 72x - 12
Let a = 7x
a = a2 - 12
a2 - a - 12 = 0
(a - 4)(a + 3) = 0
7x = 4 or 7x = -3; this is illogical so they meet at y = 4
ii.) 7x = 4
log7x = log4
xlog7 = log4
x = log4/log7
x = 0.712 to three significant figures
a.) h = 0.25
x = 0, y = 0; x = 0.25, y = 0.0263; x = 0.5, y = 0.0969; x = 0.75, y = 0.1938; x = 1, y = 0.3010
0.25 × 0.5[(0 + 0.3010) + 2(0.0263 + 0.0969 + 0.1938)]
= 0.117 to 3 significant figures
b.) Translated by: 
c.) i.) log1010 + log10x2
log1010 + 2log10x
1 + 2log10x
ii.) 1 + 2log10x = log10(10x2) = log10(√10x)2 = 2log10(√10x)
Stretch parallel to the x-axis scale factor of 1/√10
iii.) 1 + 2log10x = log10(x2 + 1)
log10(10x2) = log10(x2 + 1)
10x2 = x2 + 1
x2 = 1/9
x = 1/3 as x > 0
mOP = log10(10(1/3)2) ÷ 1/3
mOP = 3log10(10/9)
mOP = log10(1000/729)
Monday, 4 June 2012
Deriving the Quadratic Formula
If you have studied Maths up to GCSE level then it is likely that you will have encountered a method of solving any quadratic equation (an equation of the form ax² + bx + c = 0) using the quadratic formula.
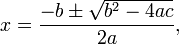
This formula is used to find where the quadratic equation crosses the x-axis (this is at y = 0). Although you have encountered this formula at GCSE it is unlikely that you will have encountered the proof as to why the formula works, which is a shame as it ties in some other GCSE Maths nicely and is in no way complex.
To solve ax² + bx + c = 0 for x you begin by completing the square, rearrange and find what x equals, simple!

And there it is, the quadratic formula! As you can see, it really isn't very difficult to derive the formula and it is a great shame that teachers do not take to the time to show students why the formula works rather than just letting them blindly accept it.
This formula is used to find where the quadratic equation crosses the x-axis (this is at y = 0). Although you have encountered this formula at GCSE it is unlikely that you will have encountered the proof as to why the formula works, which is a shame as it ties in some other GCSE Maths nicely and is in no way complex.
To solve ax² + bx + c = 0 for x you begin by completing the square, rearrange and find what x equals, simple!
Saturday, 2 June 2012
Do You Exist?
This may seem somewhat ludicrous to even consider that you may not exist. I mean, you do things, you interact with people, you feel things so obviously you exist, right? Well, not necessarily...
The problem with proving whether or not you exist is that it is very hard to even pin down what existence actually is. It is defined in the dictionary as "objective reality or being", but that poses yet more questions; if we do not know what existence is how can we begin to comprehend reality?
Within mathematics in order to prove something you must only use something that is an already proved axiom. Multiplication works because it is essentially multiple additions (2 × 3 is the same as 2 + 2 + 2). And in fact addition can be proved to be true using something simpler, something more fundamental than itself; logic. You can prove that one plus one equals two (or if you prefer a well explained video), and from this simple fact all other vastly complex mathematics can be used and proved in the knowledge that it is correct.
But existence can not be tackled in the same manner, it is the most fundamental property. Existence precedes even the most basic mathematical principles. We must exist for anything to hold true, including maths. It has to be taken as a given for our principles of logic, maths, science, everything to be true. But this does not prove that we exist. Unfortunately everything else functioning so well because of one assumption does not prove the assumption, it could just be that everything else is radically wrong.
And the main problem of trying to understand our existence - you cannot attack it with maths. You cannot break existence down into a mathematical problem so ones perception of what does, or does not constitute existence is merely subjective. When opinions are the dominant factors of an argument you can never reach a correct answer because essentially, there is none.
I can feel the philosophers amongst you grinding at your teeth, beginning to pound at your keyboard reciting Descartes quote as if it were the ultimate truth. For those of you who do not know of Descartes, he also pondered whether or not he existed but then saw that if he was able to actually ponder his existence then there must on some level be something that exists to do the pondering; hence his quote "I think, therefore I am". It is a well constructed argument, it concisely answers the question using a very logical approach. But that in itself is it's downfall, it uses logic. Logic is something that can only function as a tool if in fact there is existence on some level, so actually he uses the fact that we exist to prove that we exist.
Also, why does the property of thinking create existence? This plays on the difficulty on defining what existence actually is. It almost defines existence as thinking, then citing the fact that we do think to be a proof of existence, which is fundamentally wrong.
So, do you exist? Probably. There is no real means of actually answering the question when we cannot truly define existence. But if you do not exist and your whole life and world is not truly there, you are none the wiser and will never truly know, so why does it matter? Ignorance is bliss as they say. If you wish to believe that you exist, then you exist.
The problem with proving whether or not you exist is that it is very hard to even pin down what existence actually is. It is defined in the dictionary as "objective reality or being", but that poses yet more questions; if we do not know what existence is how can we begin to comprehend reality?
Within mathematics in order to prove something you must only use something that is an already proved axiom. Multiplication works because it is essentially multiple additions (2 × 3 is the same as 2 + 2 + 2). And in fact addition can be proved to be true using something simpler, something more fundamental than itself; logic. You can prove that one plus one equals two (or if you prefer a well explained video), and from this simple fact all other vastly complex mathematics can be used and proved in the knowledge that it is correct.
But existence can not be tackled in the same manner, it is the most fundamental property. Existence precedes even the most basic mathematical principles. We must exist for anything to hold true, including maths. It has to be taken as a given for our principles of logic, maths, science, everything to be true. But this does not prove that we exist. Unfortunately everything else functioning so well because of one assumption does not prove the assumption, it could just be that everything else is radically wrong.
And the main problem of trying to understand our existence - you cannot attack it with maths. You cannot break existence down into a mathematical problem so ones perception of what does, or does not constitute existence is merely subjective. When opinions are the dominant factors of an argument you can never reach a correct answer because essentially, there is none.
I can feel the philosophers amongst you grinding at your teeth, beginning to pound at your keyboard reciting Descartes quote as if it were the ultimate truth. For those of you who do not know of Descartes, he also pondered whether or not he existed but then saw that if he was able to actually ponder his existence then there must on some level be something that exists to do the pondering; hence his quote "I think, therefore I am". It is a well constructed argument, it concisely answers the question using a very logical approach. But that in itself is it's downfall, it uses logic. Logic is something that can only function as a tool if in fact there is existence on some level, so actually he uses the fact that we exist to prove that we exist.
Also, why does the property of thinking create existence? This plays on the difficulty on defining what existence actually is. It almost defines existence as thinking, then citing the fact that we do think to be a proof of existence, which is fundamentally wrong.
So, do you exist? Probably. There is no real means of actually answering the question when we cannot truly define existence. But if you do not exist and your whole life and world is not truly there, you are none the wiser and will never truly know, so why does it matter? Ignorance is bliss as they say. If you wish to believe that you exist, then you exist.
Thursday, 17 May 2012
SOLVED: Challenge Question 1
If you are the first to solve this problem I will give you complete set of the Richard Feynman Lectures on Physics (read up upon the Feynman Lectures on Physics).
Question:
Take a square of arbitrary side length and construct four new squares with a side length half of the original positioned in the corners a quarter of the way down and across the two sides creating the corner. This would look like:

Then in each of the new squares in the furthest corner from the first square create a new square with half the side length a quarter of the way down and across the two sides creating the corner. Repeat this step for each newly constructed square to it infinity. To help visualise this I have created another graphic:

The question is, what proportion of the total area of the squares are overlapping with another square?
Leave answers either in the comments box or contact me with the answer through our contact page or email me at rouge.ray@gmail.com.
Question:
Take a square of arbitrary side length and construct four new squares with a side length half of the original positioned in the corners a quarter of the way down and across the two sides creating the corner. This would look like:

Then in each of the new squares in the furthest corner from the first square create a new square with half the side length a quarter of the way down and across the two sides creating the corner. Repeat this step for each newly constructed square to it infinity. To help visualise this I have created another graphic:

The question is, what proportion of the total area of the squares are overlapping with another square?
Leave answers either in the comments box or contact me with the answer through our contact page or email me at rouge.ray@gmail.com.
Saturday, 7 April 2012
Introductory Mechanics: Maths of Snooker
You may have never thought exactly why a ball actually stops moving, just that it loses speed and stops. But this means that there is a deceleration (in fact this is incorrect terminology, it is better to say negative acceleration). Newton's laws of motion is where the mechanics begins to come into play, his first law is that a body remains a constant velocity or at rest unless an external force is applied.
As there is a negative acceleration when a snooker ball is hit it means that there must be another external force on the ball besides the force that was applied when it was hit, in fact there are three forces acting upon it. The weight of the ball (note that weight and mass are different!), the reaction force of the object, and the friction between the ball and the cloth. You may be thinking what about when the ball is hit, surely that is a force? And it is! But, that is a non-constant force, it is applied just once and as it is not constant it does not affect the acceleration of the ball.

And we do know what the coefficient of friction is between a snooker ball and the cloth, it is 0.5 and the mass of each ball is roughly 0.15kg. The gravitational field strength of Earth is about 9.81 ms-2, this means that we can work out what the weight and the friction is between the ball and the cloth. W = 0.15kg × 9.81 ms-2, which gives W = 1.47N. Now that we have the weight we can work out what the friction between the ball and the cloth with the friction coefficient, F = 0.5 × 1.47N, which gives F = 0.736N. We now know the three constant forces acting on the snooker ball, only one actually moves the ball in anyway, and that is the friction.
So a person supplies an initial force to the ball, which gives the ball an instantaneous velocity in the direction it was hit. But this force is not constant so friction kicks in immediately and slows the ball down, but at what rate? Using Newton's second law of motion (Force = Mass × Acceleration), a = 0.736N ÷ 0.15kg so the acceleration is 4.9ms-2.
So we could get an estimate of when the ball would finish up if we knew where the ball started and what it's initial velocity was. But, as you will know if you have played, the cue ball slows considerably when it hits cushions or other balls and there is a reason for this; energy. The kinetic energy of the ball can be calculated initially from the formula ½mv2, where m is the mass of the ball and v is the initial velocity. When the ball hits a cushion or another ball it slows down as the energy of the ball is converted into heat and sound energy, the mass of the ball will not change (much) in a collision, which means the velocity has to decrease to compensate for the decrease in energy. There is no simple formula for working out the loss in energy from contact, which is why snooker players tend to avoid going into balls when not necessary because of the unpredictability of it.
That is all well and good, but what about actually playing a shot? Well it depends what sort of shot you wish to play, but I will talk about playing a pot. If you know the distance between the cue ball and the object ball, the object ball and the pocket and the angle between the two distances, you can work out a variety of things; I will illustrate this with an image.
 |
| The dotted lines are lengths and angles that can be worked out, the solid lines are ones that would have to be measured. |
But what does all of this actually mean? The angle θ created by the two balls and the pocket is the angle that has to be adhered to in order for the object ball to be potted. The angle α can be worked out first by working out N using the cosine rule and then using the sine rule with N and θ; ϕ can be worked out using SOHCAHTOA. Then by adding them: α + ϕ is the angle the cue ball has to be played at in order to hit the red ball at the correct angle to direct it towards to pocket. We can work out everything from here now, but first I need to introduce to SUVAT equations.
 |
| Where u is the initial velocity of an object, v is the final velocity, a is the constant acceleration, t is the time taken to do the motion and s is the displacement travelled. |
So if the cue ball is hit with some velocity, what will the velocity of the ball be when it comes into contact with the object ball? Well we know the acceleration of the ball, it is decelerating due to friction, -4.9ms-2 (both vertically and horizontally) and the distance from the cue ball to the object ball (L × cos(α + ϕ) horizontally and L × sin(α + ϕ) vertically).
So we have u, a and s and want to find v, so we need to use the equation v2 = u2 + 2as. Inputting this information into the equation gives that (horizontally) vh = √[u2 - 9.8Lcos(α + ϕ)] and vertically vv = √[u2 - 9.8Lsin(α + ϕ)]. You may notice that this means if the initial velocity of the cue ball is struck at less than √[9.8Lcos(α + ϕ)] horizontally and √[9.8Lsin(α + ϕ)] vertically it will not reach the object ball.
How fast the object ball will travel depends on how fast the cue ball is struck, obviously. But what velocity does the object ball need to be struck at initially in order for the ball to go in?
To work this out is pretty simple, we need to know the distance the ball has to travel, the angle created from the line between then object ball and the pocket and the horizontal line from the ball (we'll call it λ) is equal to θ + α + ϕ - 180. We know that the final velocity has to be greater than 0 (v > 0) and the acceleration is -4.9ms-2 (both vertically and horizontally). So we know v, a and s and want to find u, so we need to use v2 = u2 + 2as again. Inputting the values we have we get horizontally uh > √[v2 + 9.8Mcos(λ)] and vertically uv > √[v2 + 9.8Msin(λ)]. This tells you how fast the object ball has to go, but not how fast the cue ball has to go initially.
To work this out we need to use the conservation of momentum (Momentum = Mass × Velocity), the conservation of momentum states that momentum before a collision = momentum after the collision. Both balls have a mass of 0.15kg. The initial momentum is 0.15 × u, after the collision the balls move at right angles to each other with the same speed, this means that:
 |
| Where λ = θ + α + ϕ - 180, M is the distance between the object ball and the pocket and v is the velocity you want the object ball to finish with. |
If you want the minimum velocity the cue ball has to be struck at for the object ball to go into the pocket you simply let v = 0 which gives you:

As you can see, this is a pretty tough calculation and not something you want to have to do before every shot! But the human brain is a remarkable thing and it is able to not do calculations of this magnitude by using past experiences to predict about where to hit the cue ball to hit the object ball in the correct way with the correct pace.
Some of the maths here would not work for an angle on the different side, or behind the ball, etc. You would need to remodel what I have done slightly, but it would just mean creating relationships between triangles slightly differently. I did skim over some mathematical steps in this post because it would have required a lot more text and potentially disengaged readers, if you have any problems with any of the maths here please leave a comment and I will explain.
Wednesday, 4 April 2012
Solving Trigonometric Equations
If you have done maths up to any level past the age of 14 it is likely that you have encountered trigonometry in some shape or form. You may remember SOHCAHTOA, meaning sin(x) = opposite/adjacent in a right angled triangle; and this is the simplest form of trigonometry you will have encountered.
It is likely that you have also encountered some basic trigonometric equations. A basic equation would be cos(x) = 1, and you may know that this means that x = 0; but this is not the only value of x that solves the equation. If you have ever gone far enough as to draw the graphs then you may have noticed that there are multiple solutions to every trigonometric equation. This is because trigonometric functions are periodic, so they repeat values of y for different values of x.
To illustrate this consider cos(x) = a, let cos(α) = a, this means that α is a solution to the equation. But it isn't the only one, I will show this on the graph of y = cos(x); note that the graph is in radians and I will be explaining in terms of radians, if you do not understand please leave a comment.
So we know that the first solution is for x = α, but what are the next ones? You have to look at when the graph repeats itself. The cosine graph has a period of 2π and it is symmetrical at x = 0, 2π, ..., 2nπ; this means that cos(x) = cos(-x). This implies that x = ±α at least, and as the function repeats every 2π you can add that on to x again and again to get the same result. This means that if cos(x) = cos(α) then x = 2πn ± α. This gives us a general solution to cosine function!
Now to do with sin. Suppose that we have a solution to some equation involving sin where sin(x) = sin(α). Again you have to look at the sine graph for when it repeats itself and where it has lines of symmetry. In fact the sine graph is the same as the cosine graph, just it has been translated to the right by π/2, this means it still repeats every 2π but the line of symmetries are at x = π/2, 3π/2, ...(2n-1)π/2. The first of these mean that when it is an even multiple of π you can find another solution by adding α that is: x = 2πn + α. The second of these mean that whenever it is an odd multiple of π subtracting α gives another solution, that is: x = (2n+1)π + α. To find a range of solutions for sin(x) = sin(α) then x = 2πn + α or 2πn + π + α. This gives us a general solution to sine function!
- cos2Ө + sin2Ө = 1; this is required for Core 2 and beyond.
- cosӨ/sinӨ = cotӨ; this is required for Core 3 and beyond.
- tan2Ө + 1 = sec2Ө ; this is required for Core 3 and beyond.
- cot2Ө + 1 = cosec2Ө; this is required for Core 3 and beyond.
- sin(A + B) = sinAcosB + cosAsinB; this is required for Core 4.
- cos(A + B) = cosAcosB - sinAsinB; this is required for Core 4.
- sin(A - B) = sinAcosB - cosAsinB; this is required for Core 4.
- cos(A - B) = cosAcosB + sinAsinB; this is required for Core 4.
- tan(A ± B) = (tanA ± tanB) / (1 ∓ tanAtanB); this is required for Core 4.
- sin2Ө = 2sinӨcosӨ; this is required for Core 4.
- cos2Ө = 1 - 2sin2Ө; this is required for Core 4.
- tan2Ө = 2tanӨ / (1 - 2tan2Ө); this is required for Core 4.
- sin3Ө = 3sinӨ - 4sin3Ө; this is required for Core 4.
- cos3Ө = 4cos3Ө - 3cosӨ; this is required for Core 4.
- tan3Ө = (3tanӨ - tan3Ө) / (1 - 3tan2Ө); this is required for Core 4.
It is likely that you have also encountered some basic trigonometric equations. A basic equation would be cos(x) = 1, and you may know that this means that x = 0; but this is not the only value of x that solves the equation. If you have ever gone far enough as to draw the graphs then you may have noticed that there are multiple solutions to every trigonometric equation. This is because trigonometric functions are periodic, so they repeat values of y for different values of x.
To illustrate this consider cos(x) = a, let cos(α) = a, this means that α is a solution to the equation. But it isn't the only one, I will show this on the graph of y = cos(x); note that the graph is in radians and I will be explaining in terms of radians, if you do not understand please leave a comment.
.png) |
| Each red dot represents a solution to an equation involving cos(x). Notice how they all lay on a horizontal line. |
Now to do with sin. Suppose that we have a solution to some equation involving sin where sin(x) = sin(α). Again you have to look at the sine graph for when it repeats itself and where it has lines of symmetry. In fact the sine graph is the same as the cosine graph, just it has been translated to the right by π/2, this means it still repeats every 2π but the line of symmetries are at x = π/2, 3π/2, ...(2n-1)π/2. The first of these mean that when it is an even multiple of π you can find another solution by adding α that is: x = 2πn + α. The second of these mean that whenever it is an odd multiple of π subtracting α gives another solution, that is: x = (2n+1)π + α. To find a range of solutions for sin(x) = sin(α) then x = 2πn + α or 2πn + π + α. This gives us a general solution to sine function!
{kind=link}
And the easiest one of all is finding solutions to tan(x) = tan(α). The tan graph repeats every π and has no lines of symmetry. This simply means that if x = α, it also equals π + α and 2π + α, etc. To find a range of solutions for tan(x) = tan(α) then x = πn + α. This gives a general solution to the tangent function!
That is fine for when you have simple trigonometric equations, but what if you have one that contains more than one trigonometric function? Well there are trigonometric identities that help you to rearrange equations into a form that is easier to solve. I will simply list them in this post, but I will prove them in a later post. For UK readers, next to the identity I will state in which module you need to utilise them in.
- sinӨ/cosӨ = tanӨ; this is required for Core 2 and beyond.- cos2Ө + sin2Ө = 1; this is required for Core 2 and beyond.
- cosӨ/sinӨ = cotӨ; this is required for Core 3 and beyond.
- tan2Ө + 1 = sec2Ө ; this is required for Core 3 and beyond.
- cot2Ө + 1 = cosec2Ө; this is required for Core 3 and beyond.
- sin(A + B) = sinAcosB + cosAsinB; this is required for Core 4.
- cos(A + B) = cosAcosB - sinAsinB; this is required for Core 4.
- sin(A - B) = sinAcosB - cosAsinB; this is required for Core 4.
- cos(A - B) = cosAcosB + sinAsinB; this is required for Core 4.
- tan(A ± B) = (tanA ± tanB) / (1 ∓ tanAtanB); this is required for Core 4.
- sin2Ө = 2sinӨcosӨ; this is required for Core 4.
- cos2Ө = 1 - 2sin2Ө; this is required for Core 4.
- tan2Ө = 2tanӨ / (1 - 2tan2Ө); this is required for Core 4.
- sin3Ө = 3sinӨ - 4sin3Ө; this is required for Core 4.
- cos3Ө = 4cos3Ө - 3cosӨ; this is required for Core 4.
- tan3Ө = (3tanӨ - tan3Ө) / (1 - 3tan2Ө); this is required for Core 4.
Subscribe to:
Posts (Atom)